1. 데이터 베이스
일정한 규칙에 따라 구조화되어 저장되어 있는 데이터의 모음.
2. DBMS(DataBase Management System)
데이터베이스를 생성, 조작, 관리하는 역할을 한다. 데이터를 query language를 통해서 삽입, 조회, 수정, 삭제할 수 있다. DBMS는 데이터베이스 시스템의 핵심 부분으로 사용자와 응용프로그램이 데이터를 효율적으로 조작, 관리할 수 있도록 응용프로그램과 데이터베이스 사이에서 인터페이스 역할을 한다.
3. 엔티티(데이터베이스에 저장하려는 실제 항목을 나타내는 추상적인 개념)
엔티티는 데이터베이스에서 현실 세계에서 식별가능한 하나의 객체, 사물, 개념 또는 사건을 나타내는 추상적인 개념이다. (객체지향에서 설명하는 객체와 비슷하다.) 데이터베이스 내에서 테이블로 표현되며, 각 엔티티는 해당하는 속성과 관련된 데이터를 포함하게 된다. 주문이라는 엔티티가 있다고 가정했을 때, 주문번호, 주문금액, 주문주소 등의 속성 값이 존재할 수 있다.
엔티티의 주요 특징
1. 유일성: 각 엔티티는 고유한 식별자(Primary Key)를 가지며, 이를 통해 다른 엔티티와 구별 된다.
2. 속성: 엔티티는 속성(Attribute)을 가지며, 이는 엔티티의 특성을 설명하는 데이터 값이다.
3. 관계: 여러 엔티티 간에는 관계가 존재할 수 있으며 이를 통해 엔티티들 간의 연결과 상호작용을 표현할 수 있다.
4. 예시로는 "고객", "주문", "제품" 등과 같은 현실세계의 객체들을 엔티티로 표현할 수 있다.
3. 릴레이션 (관계형 데이터베이스에서 테이블을 나타내는 개념)
데이터베이스에서 정보를 구분하여 저장하는 기본 단위. 엔티티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리한다. 예를 들어 회원이라는 엔티티를 데이터베이스에 저장할 때 회원 테이블을 만들고 그 안에 엔티티들의 속성들을 컬럼으로 하여금 하나의 릴레이션(테이블)로 관리한다.
릴레이션(테이블)의 주요 특징
1. Row(행): 릴레이션 내에 각 행은 특정한 데이터 요소의 집합을 나타낸다. 고객 릴레이션의 각 행은 하나의 고객에 대한 정보를 포함한다.
2. Column(열): 릴레이션의 각 열은 해당 데이터의 특정한 속성을 나타낸다. 고객 릴레이션에서 각 열은 이름, 주소, 전화번호등이 될 수 있다.
3. Key(키): 릴레이션 내에서 한 개 이상의 열을 식별자로 선택(단일키, 복합키)하여, 특정 행을 고유하게 식별하는데 사용된다. 이를 Primary Key라고 부르며 주 키를 사용해서 다른 릴레이션과의 관계를 형성한다.
4. Attribute(속성): column(열)은 릴레이션의 속성을 나타냄. 각 속성은 특정한 유형의 데이터 값을 가지고 있고, 열을 통해 속성을 식별한다.
5. 데이터 정렬: 릴레이션 내의 데이터는 열에 따라 정렬되지 않은 순서로 저장됨. 데이터의 순서는 중요하지 않으며, 데이터를 필요한 순서대로 검색할 경우에는 쿼리를 사용하여 정렬할 수 있다.
테이블과 컬렉션
데이터베이스의 종류는 크게 RDB와 NoSQL로 나눌수 있다. 각 DB에 따라 테이블을 부르는 용어가 조금씩 차이가 있다.
| DB | 개별 데이터를 부르는 용어(행) | 개별데이터의 집합을 부르는 용어 |
| MySQL(RDB) | 레코드 | 테이블 |
| MonghDB(NoSQL) | 도큐먼트 | 컬렉션 |
| ElasticSearch(NoSQL) | 도큐먼트 | 인덱스 |
4. 속성(Attribute)
속성은 엔티티나 릴레이션에서 가지고 있는 특정한 데이터의 특성을 나타내는 단위다. 예를 들어 고객이라는 엔티티가 있다고 가정한다면 고객이 가지고 있는 속성으로는 이름, 성별, 나이 등이 될 수 있다. 이 중에 요구사항에 따라 데이터를 관리해야 할 필요가 있는 것들이 엔티티의 속성이 된다.
5. 도메인(Domain)
도메인은 데이터베이스에서 각각의 속성의 허용되는 값의 범위 또는 유효한 값들의 집합을 나타낸다. 예를 들면 회원 테이블에서 성별이라는 속성이 있고, 그 속성의 도메인은 {남,여} 이다. 속성 값에 들어갈 수 있는 값의 범위 또는 집합을 의미한다.
6. 필드와 레코드(Field, Record)
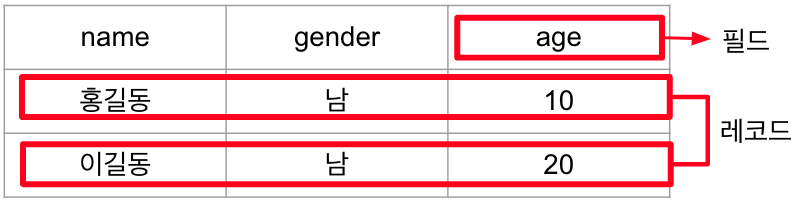
필드 타입
1. 숫자 타입 (타입은 각 DB마다 다르다. MySQL 기준으로 정리)

2. 날짜 타입
- DATE
날짜 부분은 있지만 시간은 없는 값에 사용. 범위는 1000-01-01 ~ 9999-12-31. 용량은 3바이트
- DATETIME
날짜 및 시간 부분을 모두 포함하는 값에 사용. 범위는 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59. 용량은 8바이트
- TIMESTAMP
날짜 및 시간 부분을 모두 포함하는 값에 사용. 범위는 1970-01-01 00:00:01에서 2038-01-19 03:14:07까지 지원. 용량은 4바이트.
3. 문자 타입
- CHAR와 VARCHAR
둘 다 문자열을 저장할 때 사용한다.
CHAR는 테이블을 생성할 때 선언한 길이로 고정. 범위는 0~255. 레코드를 저장하면 무조건 선언한 길이 값으로 고정해서 저장.
VARCHAR는 가변길이 문자열. 범위는 0~65535 사이의 값을 가질 수 있다. 입력한 데이터에 따라 용량을 가변시켜 저장.
ex) VARCHAR(1000) 으로 선언하고, 10글자를 입력할경우 10글자에 해당하는 바이트 + 길이기록용 1바이트로 저장된다.
- TEXT와 BLOB
둘 다 큰 데이터를 저장할 때 사용한다.
TEXT는 큰 문자열 저장에 쓰고, 주로 게시판 본문을 저장할 때 사용한다.
BLOB은 이미지, 동영상 등 큰 데이터 저장에 쓴다.
그러나 보통은 아마존의 이미지 호스팅 서비스인 S3를 이용하는등 서버에 파일을 올리고 파일에 관한 경로를 VARCHAR로 저장한다.
- ENUM과 SET
ENUM과 SET 모두 문자열을 열거한 타입이다. ENUM은 ENUM('선택1', '선택2', '선택3', '선택4', '선택5') 형태로 쓰인다.
이 중에서 하나만 선택할 수 있는 단일 선택만 가능하고 리스트에 값이 없다면 빈 문자열이 대신 삽입된다.
최대 65535개의 요소를 넣을 수 있다.
ENUM을 사용하면 문자열이 0,1등의 숫자로 매핑되어 메모리를 적게 사용하는 이점을 가지지만, 단점도 존재한다.
ENUM 리스트 안에 있는 값을 변경해야 할 일이 생겼을 때 데이터 수정이 어렵다.
https://gompro.postype.com/post/8253823 - ENUM을 사용하지 말아야하는 이유를 적어놓은 블로그
SET은 ENUM과 비슷하지만 여러 개의 데이터를 선택할 수 있고, 비트 단위의 연산도 가능하다. 최대 64의 요소를 넣을 수 있다.
6. 관계
데이터 베이스는 테이블이 여러개 존재하는데 테이블들은 연관관계에 따라서 관계를 형성하고 있다. 관계화살표는 아래와 같다.

1) 1:1 관계
1:1 관계는 하나의 테이블의 레코드가 다른 테이블의 레코드와 1:1 매칭 되는 것을 의미한다. 예를들어 사람 테이블과 성별 테이블이 있다고 했을 때 사람은 하나의 성별만을 가질 수 있으므로 1:1 관계가 된다.
2) 1:N 관계
1:N 관계는 하나의 테이블의 레코드가 다른 테이블의 여러 레코드에 매칭이 될 수 있는 것을 의미한다. 예를 들면 사람 테이블과 전화번호 테이블이 있다고 가정했을 때 한 명의 사람이 여러개의 전화번호를 가질 수는 있지만 전화번호는 한 사람에게 귀속 될 수 밖에 없습니다. 이런 관계를 1:N 관계라고 한다.
3) N:M 관계
N:M관계는 두 개의 테이블이 서로 다수 : 다수로 매핑 될 수 있는 경우를 의미한다. PC방을 예로 든다면 손님 테이블과 PC테이블이 존재한다고 했을 경우 손님은 다수의 PC를 이용할 수 있고, PC도 다수의 손님이 이용할 수 있으니 다대다 관계가 된다.
7. 키
테이블 간에 관계를 맺을 때 필요하고, 인덱스를 위해서 필요하다. 종류로는 기본키, 외래키, 후보키, 슈퍼키, 대체키가 있다.

1) 기본키(Primary Key)
기본키는 PK(Primary Key)라고 불리우며 유일성과 최소성을 만족하는 키이다.
- 자연키
중복 되는 것들을 제외하고 남은 중복 되지 않는 키를 자연키라고 한다. -> 새로 컬럼을 만들지 않고, 있는거 그대로 사용.
자연키는 언젠가 변하는 속성을 가지고 있다.
- 인조키
레코드를 식별하기 위해 인위적으로 만든 키(Auto Increment). 자연키와 다르게 변하지 않는다.
-> 변하지 않는 속성 때문에 PK로 쓰기 적절하다.
2) 외래키(Foreign Key)
다른 테이블을 기본 키를 그대로 참조하는 값으로 개체와 개체간의 관계를 식별하는데 사용한다. -> 테이블간에 관계를 맺기 위해서는 FK가 필요하다. 또한 외래키는 중복이 가능하다.
3) 후보키(Candidate Key)
후보키는 기본키가 될 수 있는 후보들이며 유일성과 최소성을 동시에 만족한다.
4) 대체키(Alternate Key)
대체키는 후보키가 두 개 이상일 경우 하나를 기본키로 지정하고 남은 키들을 말한다.
5) 슈퍼키(Super Key)
슈퍼키는 각 레코드를 유일하게 식별할 수 있는 유일성을 가진 키이다.
참조
면접을 위한 CS 전공지식 노트
'프로그래밍 > DB' 카테고리의 다른 글
| unable to launch the java virtual machine located at path 오류 발생시 해결법 (0) | 2020.10.24 |
|---|---|
| Oracle Database 11g xe 설치하기 (0) | 2020.10.24 |

